MySQL 索引以及 BTree 和 B+Tree
索引
- 相当于目录
- 是帮助 MySQL 高效获取数据的数据结构
- 在 MySQL 中,数据最终是保存在硬盘上的
访问硬盘相当于是
IO操作,MySQL 有一个page的概念,一个page就是树中的一个节点,每次 MySQL 就会取出一个page也就是一个节点的数据,而 MySQL 默认一个page保存16k的数据,当然这个是可以改配置修改的。
本质的优化:就是减少IO的次数,一个page保存更多的有效数据。
二叉树
- 左子树的所有值都小于根节点
- 右子树的所有值都大于根节点
- 每个根节点最多分裂出两个子节点
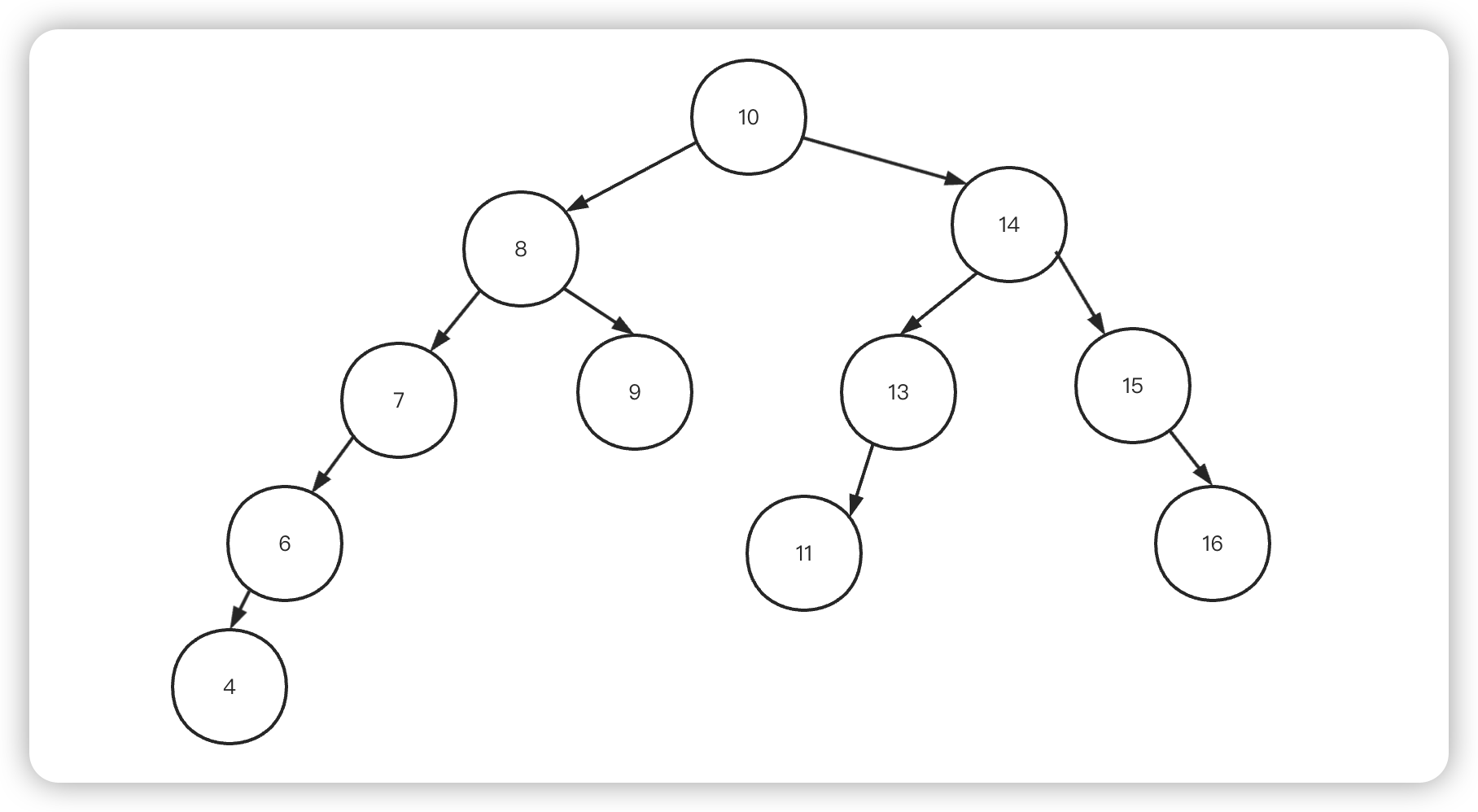
比如,我们要查找数字 9,从根节点开始,比根节点小,就从根节点左边开始查,又比左子树大,转而查找右子树,最终找到
这里经过了10->8->93 个节点,相当于经历了 3 次IO操作。
这样看起来还算是查询比较少的,但是如果有下面的特例:
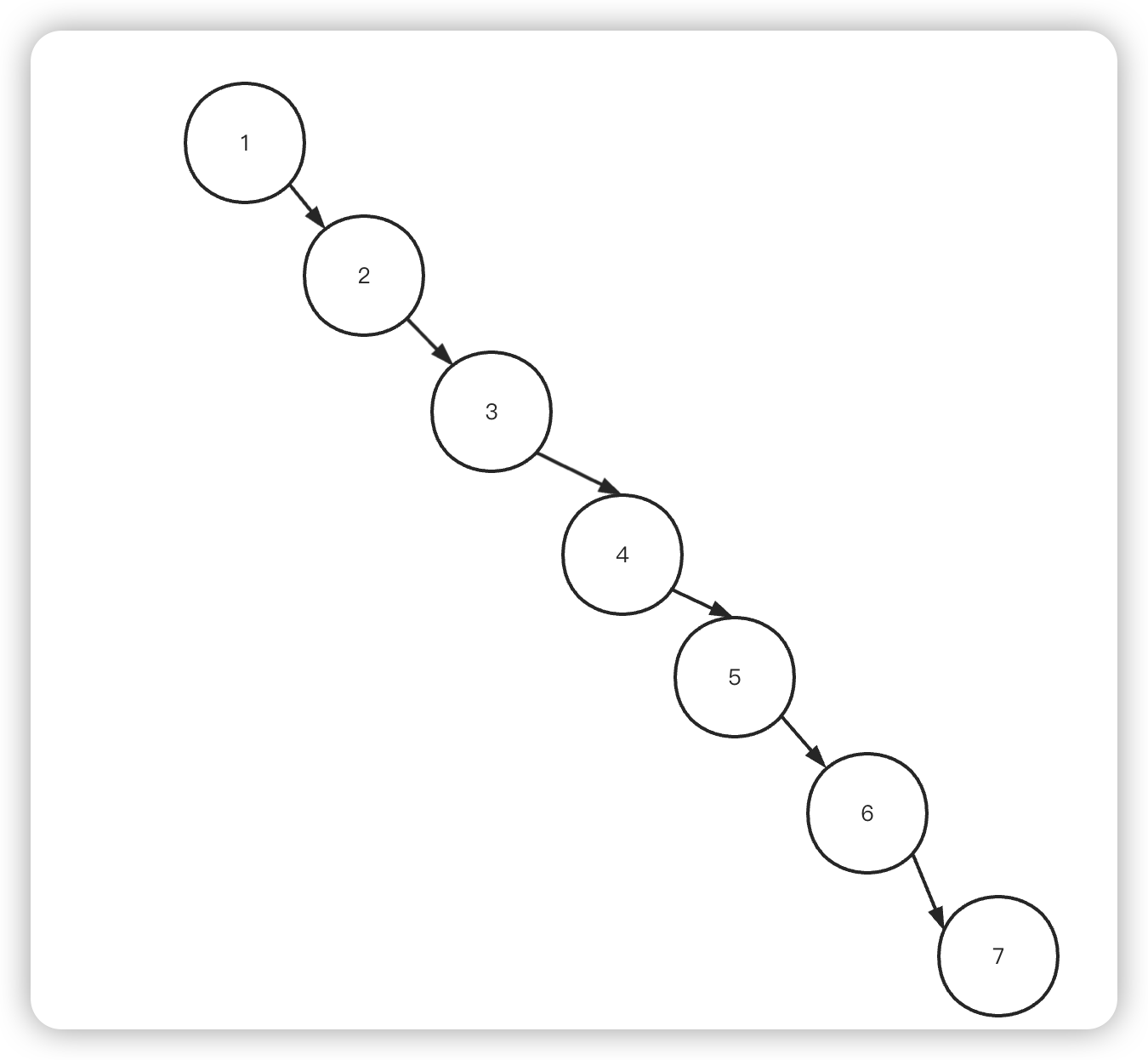
这样的树相当于一个链表格式,极端情况下,查找数字 7 就会经历 7 个节点,也就是 7 次IO,就会遍历整个表,所以就衍生出下一个平衡二叉树
平衡二叉树
- 相对平衡,左右两个子树的深度差绝对值不能超过 1,就会避免上述的极端情况
- 左右 2 个子树也必须是平衡二叉树
为啥 MySQL 又不用这个呢,是因为二叉树一个节点只有 2 个叉,只能保存一条数据 ,获取 16k 的
page,只有一条数据,造成资源浪费。
单个节点保存数据少,就会造成节点增多,树的深度就会增多,查询次数就会增多。
B-Tree
特点:多叉,阶;B 树约束了层高,B 树的叶子节点在统一的高度上面
- 1 个节点可以存储超过 2 个元素,可以拥有超过 2 个子节点
- 拥有二叉树的一些性质
- 平衡、每个节点的所有子树高度一致
- 比较矮【层数低】
性质:m阶【阶表示有多少个叉】B 数,最多拥有m个子节点
元素个数:假设一个节点存储的元素个数为x
- 根节点:
1 <= x <= m-1 - 非根节点:(向上取整)
m/2 <= x <= m - 1
子节点个数:y = x + 1
- 根节点:
2 <= y <= m - 非根节点:(向上取整)
m/2 <= y <= m - 每个节点最多有
m个子节点 - 除根节点外,每个节点至少有
m/2个子节点,注意如果结果除不尽,就向上取整 - 根节点要么为空,要么就是独根,否则至少有 2 个子节点
- 有
k个子节点的节点必须有k个关键词,就是有m个数据就有m个叉 - 叶子节点的高度一致
画一个 BTree
首先确定一个阶数:4 阶,则每个节点的元素个数为 3
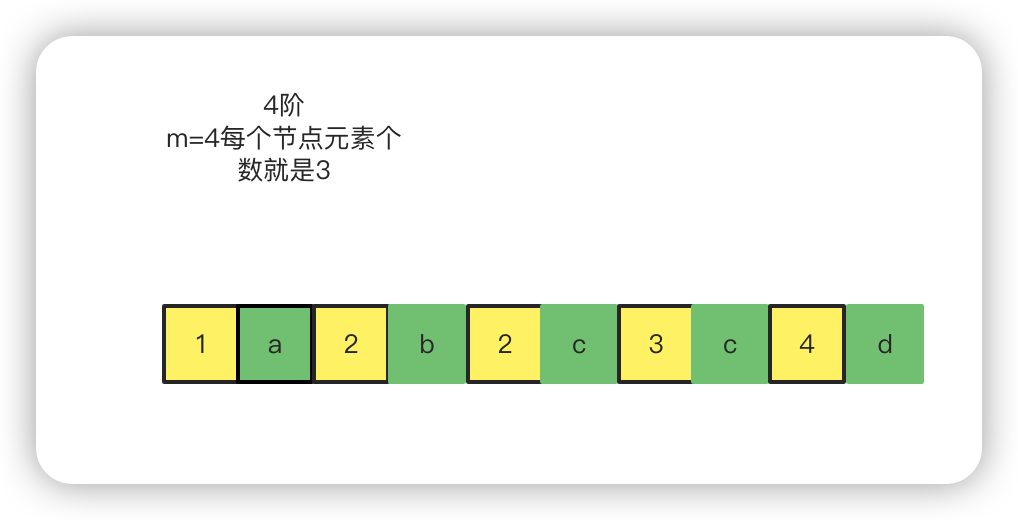
首先每个个元素由对应 id 和值组成。我们画出 4 个,然后现在元素个数已经是超出 3 个了,就需要分层,一般取中间的值,自己定下去中间靠前的还是中间靠后的,现在是偶数,我们取 id 为 2 的元素,上提,然后会有一个指针p分别指向第一个和第 3 个.
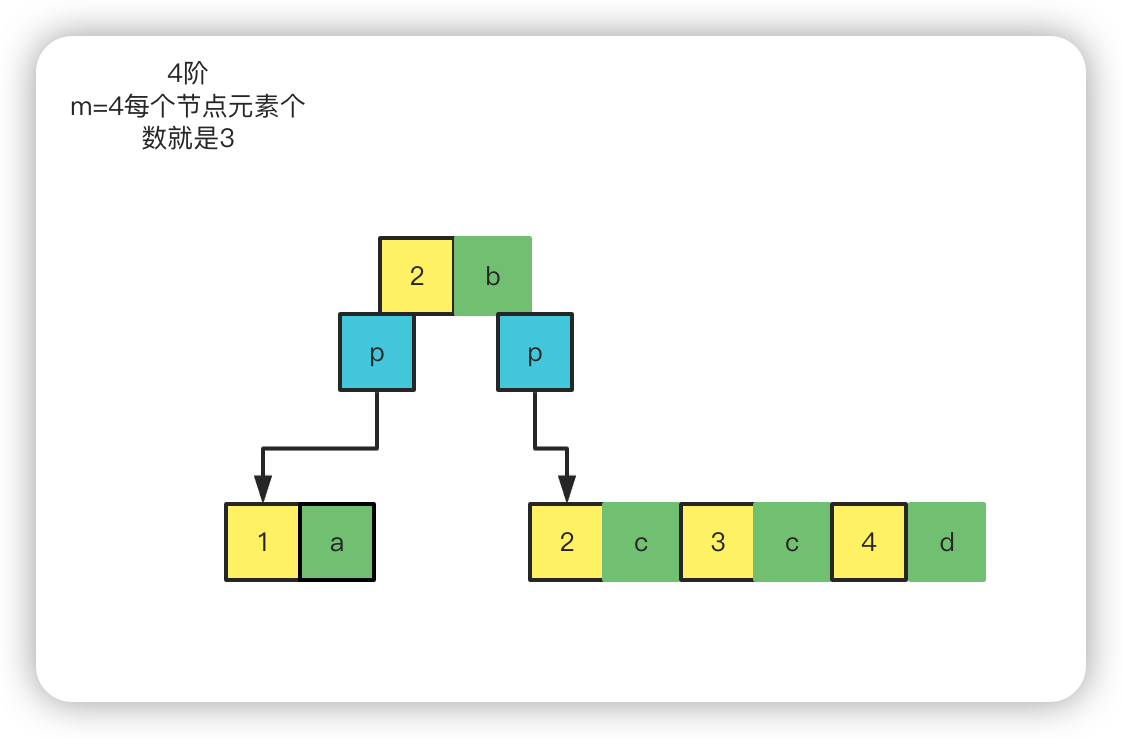
然后继续往后面添加元素,添加到 6 的时候,就又必须提,还是取中间靠前的,这次是将 4 提上去。
我这边可能数字标错了,多了 2 个 2,其实下面的 2 应该是 3,后面依次加 1
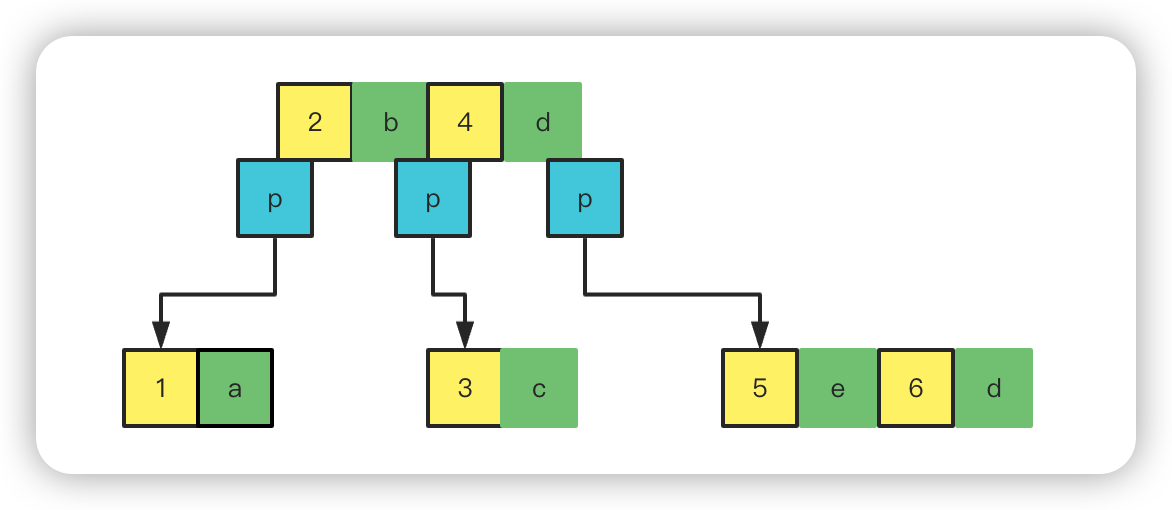
然后继续往后加元素,加到同样超过 3 个的时候就取中间靠前的往上提,加一个指针。
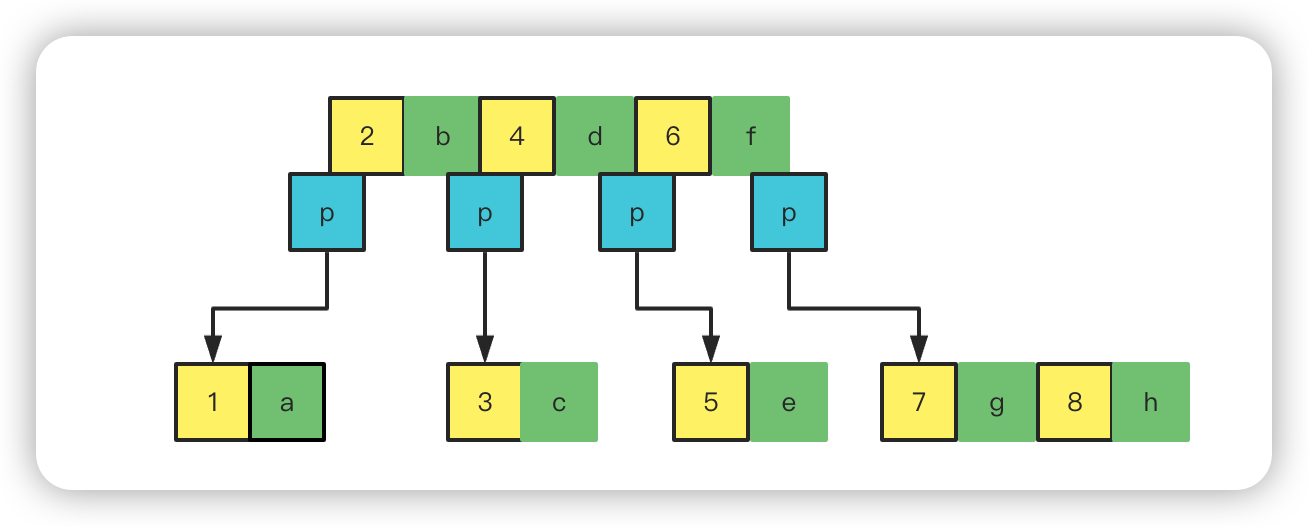
然后继续加元素,加到 10,又超过 4 个再往上提取第 8 个上去,此时上面一层也达到了超过 3 个元素了,也取中间靠前的,提取 4 再往上。
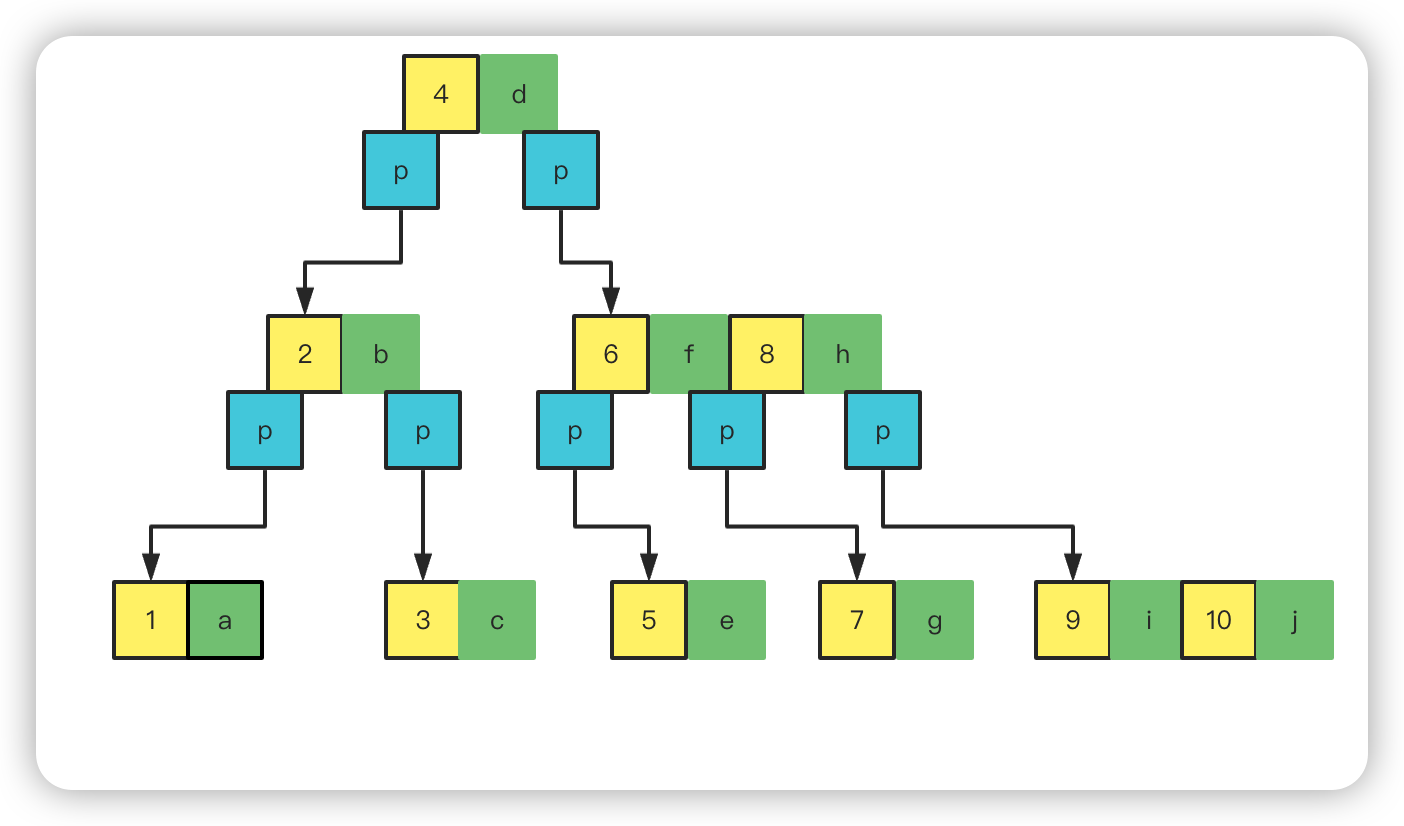
这样的一棵的 4 阶 BTree 树就完了。单个节点可以保存多个数据,一次page可以获取更多的有效数据,同时因为分叉增多,数据层级肯定会更小,查询次数就会减少。前面说一个page最多可以 16k 数据,那么一个 3 层的 B 树可以保存16*16*16=4096k的数据,保存的数据还是不多,如果一个表有五百万数据,那么它的层级还是会很深,IO也会变多。
数据从小到大一次分步在树的不同层级中,进行范围查找,获取范围越大,获取的节点就越多,IO就越多;比如获取从 1 到 10,就会把每一个节点上的值都遍历一遍,这样性能肯定就会有问题。
B+Tree
- 只在叶子节点保存数据信息,非叶子节点不保存,只保存标识和指针信息。
- 节点保存的元素个数等于 m,并且左闭右开
- 叶子节点通过指针链接,方便范围查找,只需遍历叶子节点
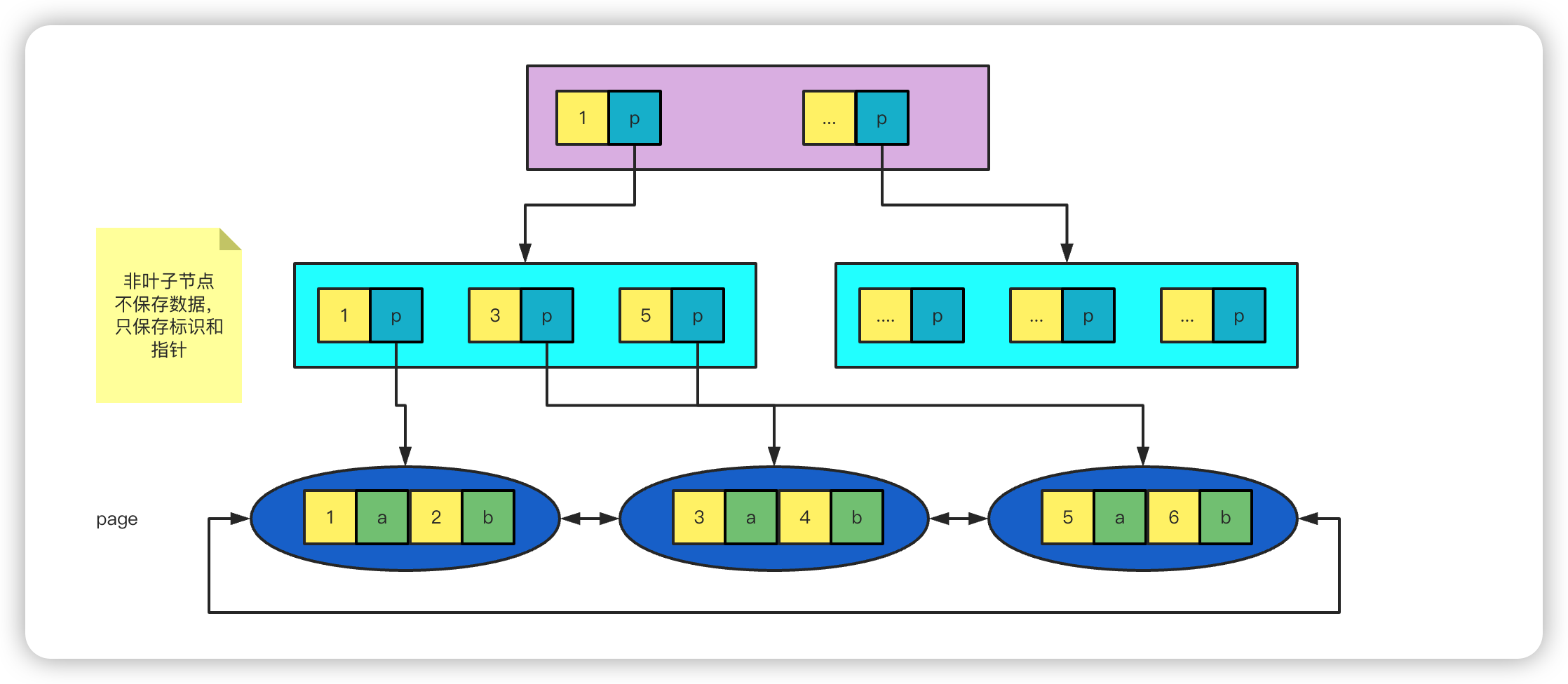
为什么 MySQL 使用 B+Tree,而不使用 B-Tree 呢?
算一下,同层的,BTree 可以保存 4096k
B+Tree,叶子结点基于索引排序更优,非叶子节点不保存数据,保存索引数据更多,一次IO获取更多的目标数据。
第二层假设保存一个标识或指针需要 6b,那么第二层可以保存:16*1024/6=2730和第三层一样,三层就可以保存:2730*2730*16≈12亿。
如何使用
MySQL 有 2 个重要的存储引擎
Myisam:文件有:*.frm、*.myi、*.myd
- frm 用于保存表的定义信息
myi用于保存索引的信息myd保存数据信息
主键索引
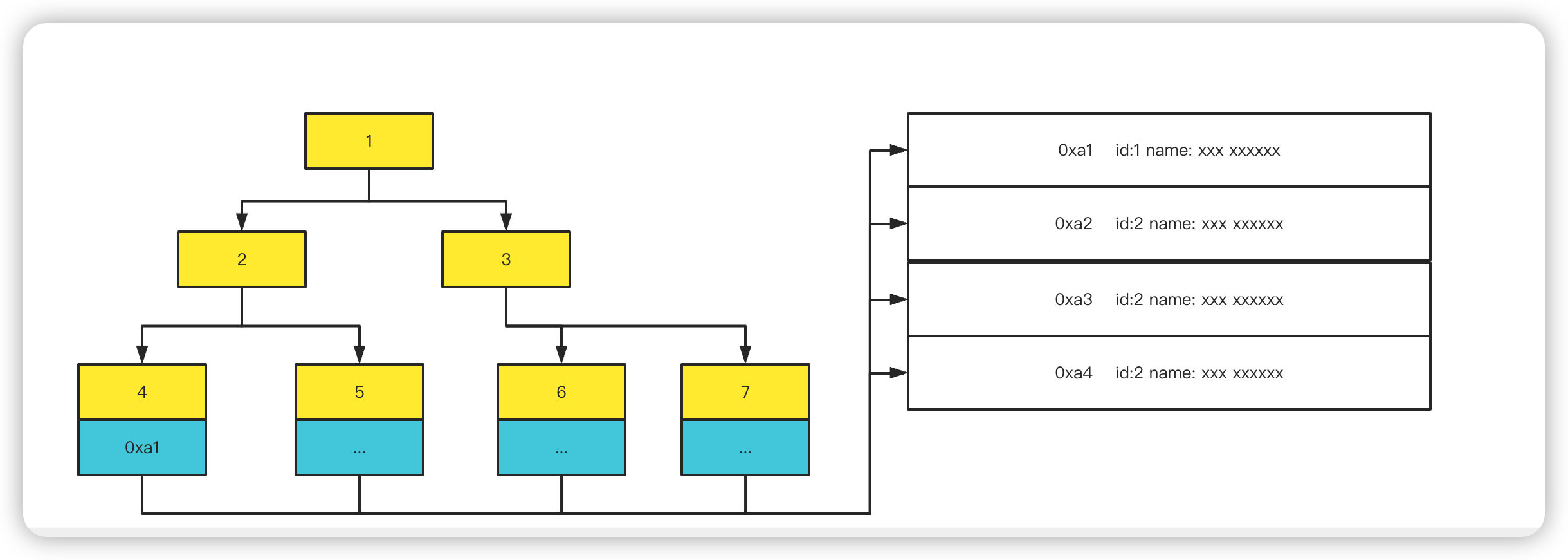
非主键索引比如name加上索引,都是和主键索引一样最下面保存的是指针,都分别执行表中的一行数据。
InnoDB 保存了 2 个文件
frm:表的定义信息ibd:保存了索引信息和数据信息
主键索引,下面的叶子节点保存了一个真正的数据,当查找该叶子节点就能直接把数据查出来。
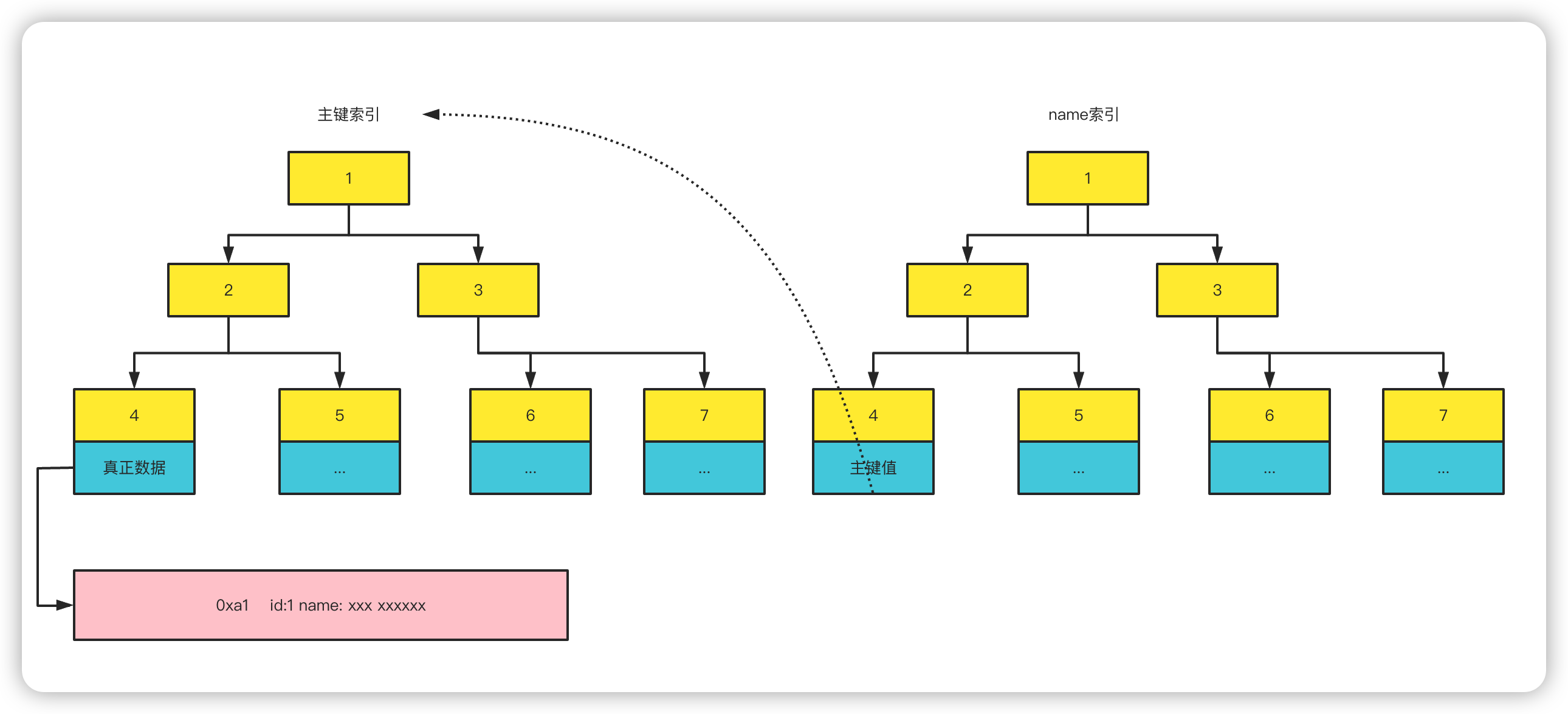
如果是name索引,它的叶子节点存储的是其主键值,然后再根据主键值去主键索引中依次查找,最终查找到最终的数据。
那么如果你不创建主键索引呢,不用担心,InnoDB会自动给你创建索引。
回表
尽量避免回表
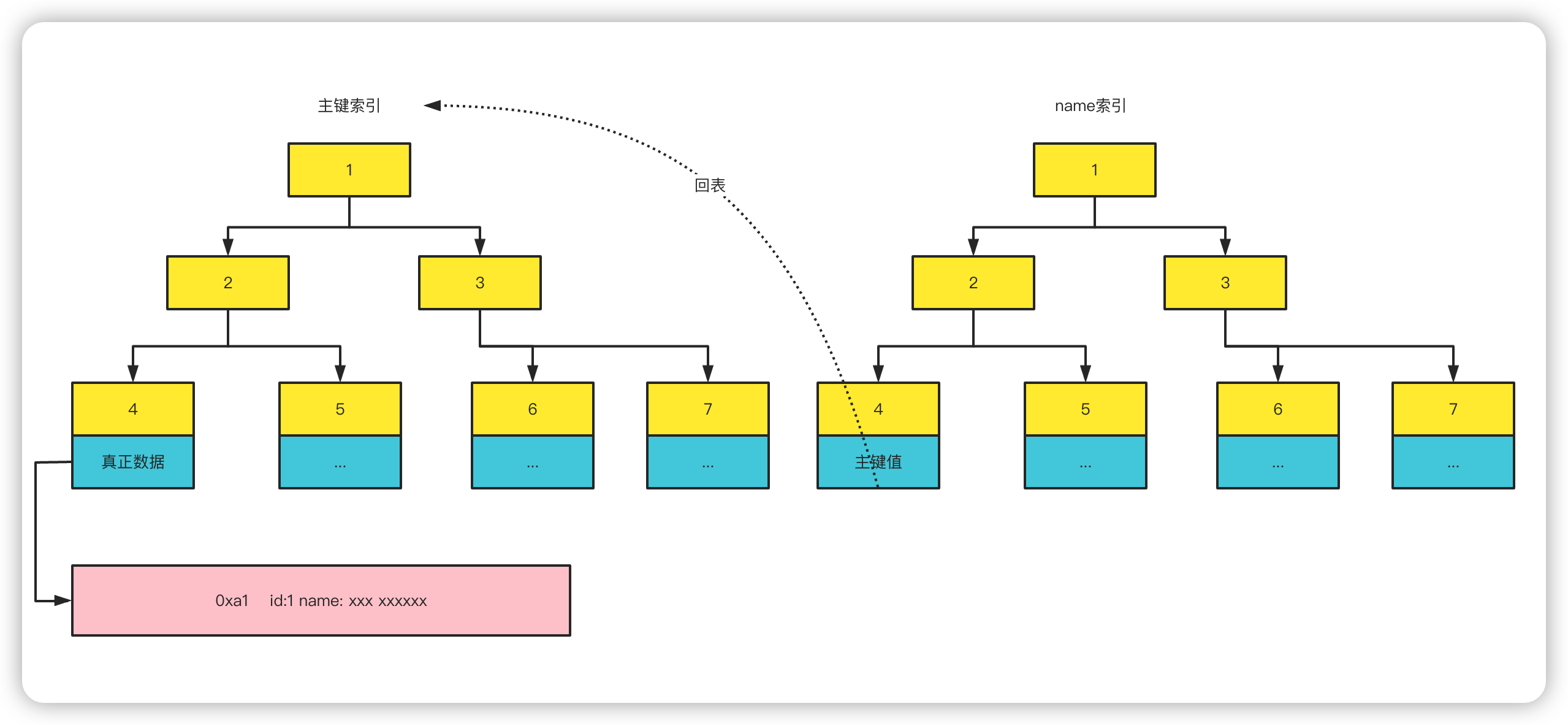
上面使用
name索引找到主键值,然后再根据主键值去主键索引里找到最终数据,这个过程就是一个回表的过程。假设现在有一个表,你设置了
id索引和name索引,有一个sql语句如下:sqlselect * from table where name = ?这个会触发回表,根据
name索引只能获取到id和name但是此时并不能满足 SQL 查询的需要,因为这里是*,假如这里不是*,就不会回表,会直接获取这 2 个数据,不用再去查找整个数据。所以会有一个尽量不要使用
select *来查询的这样的一个原因索引覆盖
就是上面同样的内容,只是
sql变成了sqlselect id, name from table where name = ?这样就不会去回表去查询住建索引。它覆盖完全了,就不用再查整个。
可以考虑将查询的列创建组合索引,避免回表;不过也不能一直增加索引,不然索引数据越来越大也会影响效率,需要进行评估对查询频率较高的列添加索引
问题
为什么不建议使用
uuid当主键,为什么建议主键 ID 是自增的,和 B+Tree 有什么关系?回答
因为创建索引的时候是按照从小到大的顺序来创建的,根据我们画的步骤来说,我们每次元素都是从最后一个节点依次添加,当不满足大小的时候就会往上提,当一个
page放满数据之后,才会放到下一个page中,这样就会保证一个page的充分利用,也就是减少了分叉,也就是减少了获取的次数;而uuid呢,它是没有任何规律的,插入的时候它就不会插入到最后一个上面,它会在这里插一个,那里插入一个,很容易多出分叉出来,到最后可能一个节点就保存了一条数据,就会造成一个page的浪费,所以不会用uuid来当主键。MySQL 中的聚簇索引和非聚簇索引如何理解?
回答
InnoDB中的主键索引就是聚簇索引,而非主键索引就是非聚簇索引,数据和索引存储在一起的就是聚簇索引,没有存储在一起的就是非聚簇索引;数据必定是和某一个索引绑定在一起的,绑定数据的就是聚簇索引;Myisam:只有非聚簇索引,它有 3 个文件组成,一个文件只保存索引信息,一个文件只保存数据信息,他们是分开的,他们都是非聚簇索引。最左匹配和
xxx%查询一定会使用到索引么?假如创建了
name, age, address的索引sqlselect * from user where name = ? and age = ? and address = ?从左到右查,先根据
name查询出来的数据,然后再此基础上再根据age查询数据,再在此基础上根据address来查询。sqlselect * from user where name = ?使用到了索引,直接根据
name拿到了数据。sqlselect * from user where name = ? and address = ?它只用到了
name,因为要查询address就必须依赖age查询出来的数据,这里没有,所以这里只用到了name索引。所以
name like 'aaa%'是用到了索引,但是把百分号放到了前面name like '%aaa',这个时候就用不到了,因为这块就是模糊的了,不定的,就用不到索引,最左匹配,最左边都是模糊的不知道,所以就不使用索引,这是通俗的说法。