主从复制和读写分离
主从复制的作用
- 写操作锁表,影响读操作,影响业务;可以让主库负责写,读库负责读,就可以避免锁表的情况,可以保证读操作的执行
- 可以实现数据的备份
- 随着数据的增加,I/O 操作增多,单机出现瓶颈,就需要多库来分担压力。
主从复制:
从一个服务器的节点复制数据到多个从节点,默认采用异步的方式;
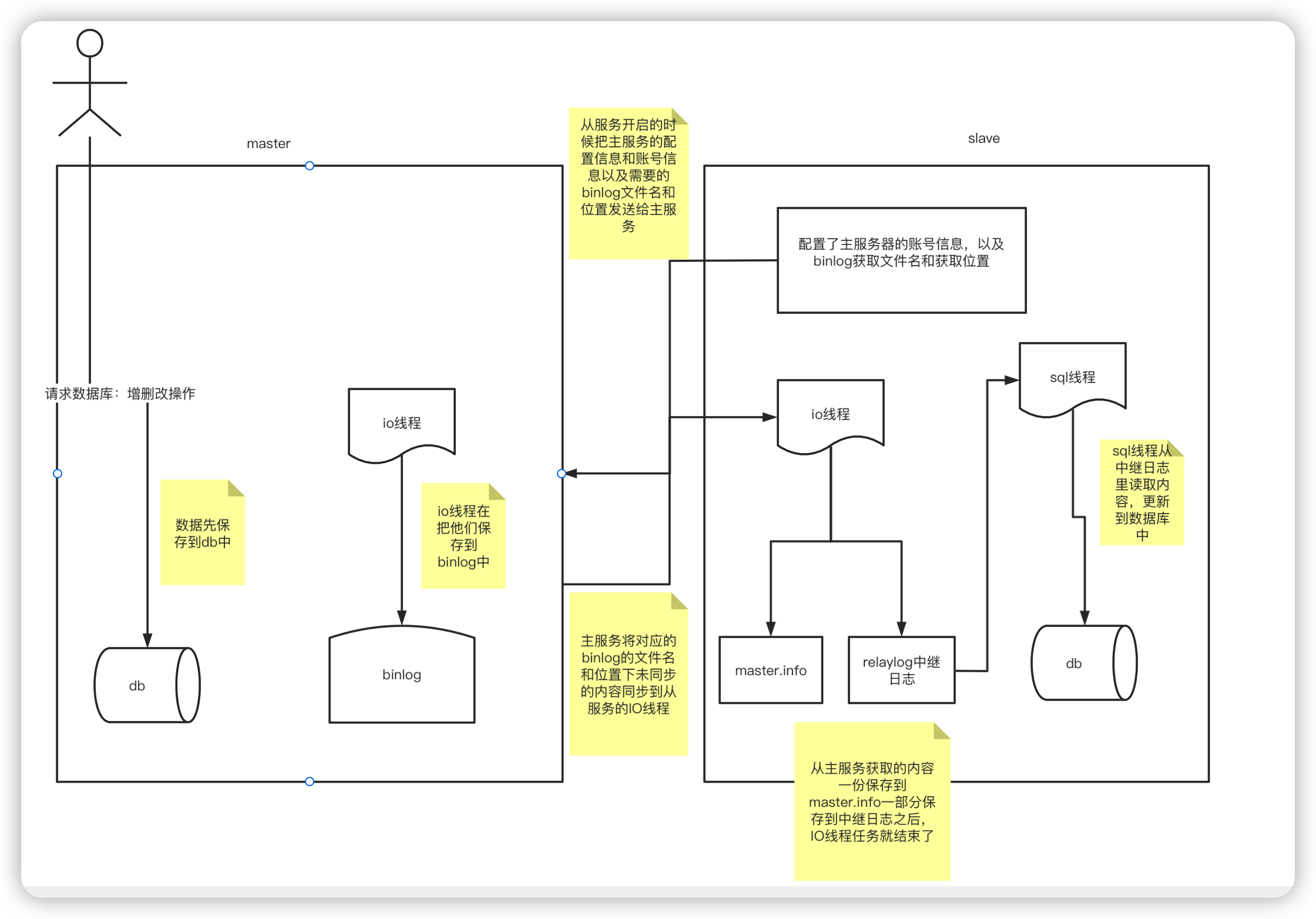
MySQL 单服务器配置多实例运行
版本:MySQL5.7
在my.cnf配置文件中增加下面的配置信息
sql
[mysqld_multi]
#mysqld = /usr/local/mysql/bin/mysqld_safe
mysqladmin = /usr/local/mysql/bin/mysqladmin
user = root
password = 123456
[mysqld3307]
server-id=3307
port=3307
log-bin=mysql-bin
log-error=/Users/username/mysql-cluster/master/mysqld.log
tmpdir=/Users/username/mysql-cluster/master
slow_query_log=on
slow_query_log_file =/Users/username/mysql-cluster/master/mysql-slow.log
long_query_time=1
socket=/Users/username/mysql-cluster/master/mysql_3307.sock
pid-file=/Users/username/mysql-cluster/master/mysql.pid
basedir=/Users/username/mysql-cluster/master
datadir=/Users/username/mysql-cluster/master/data
[mysqld3308]
server-id=3308
port=3308
log-bin=mysql-bin
log-error=/Users/username/mysql-cluster/slave/mysqld.log
tmpdir=/Users/username/mysql-cluster/slave
slow_query_log=on
slow_query_log_file =/Users/username/mysql-cluster/slave/mysql-slow.log
long_query_time=1
socket=/Users/username/mysql-cluster/slave/mysql_3308.sock
pid-file=/Users/username/mysql-cluster/slave/mysql.pid
basedir=/Users/username/mysql-cluster/slave
datadir=/Users/username/mysql-cluster/slave/data
read_only=1bash
# 执行和查看
# 启动之前杀掉所有的mysql的启动进程
killall mysqld
# 启动
mysqld_multi --defaults-extra-file=/etc/my.cnf start
# 查看启动情况
mysqld_multi --defaults-file=/etc/my.cnf report
# 登录实例
mysql -uroot -p -P3308 -h127.0.0.1
mysql -uroot -p -P3307 -h127.0.0.1各自登录上之后
sql
mysql> show variables like 'port'
-> ;
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| port | 3307 |
+---------------+-------+
1 row in set (0.01 sec)查看登录的是哪个端口的内容。
查看binlog开启了没有
sql
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.00 sec)现在是开启状态
sql
mysql> show variables like 'server_id';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 3307 |
+---------------+-------+
1 row in set (0.01 sec)
-- 另一个
mysql> show variables like 'server_id';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 3308 |
+---------------+-------+
1 row in set (0.01 sec)在主库上新建一个账户
sql
mysql> flush privileges;
mysql> create user 'copy'@'%' identified by 'copy';配置权限
sql
grant replaction slave on *.* to "copy"@"%";给copy用户附加的复制权限。
查看主库的binlog文件在什么位置
sql
show master status;
+-----------------+----------+
| File | Position | 省略
+-----------------+----------+
| mysql-bin.000005| 766 | 省略
+-----------------+----------+
1 row in set (0.00 sec)如果 主库和从库都是新建的,那就没有必要再去备份一下主库到从库复制一下;如果不是新的,那么就有必要保证两者起点是一样的。
一个导出一个导入即可。
从库配置信息
sql
CHANGE MASTER TO MASTER_HOST="127.0.0.1",MASTER_PORT=3307,MASTER_USER="copy",MASTER_PASSWORD="copy",MASTER_LOG_FILE="mysql-bin.000005",MASTER_LOG_POS=766;注意:配置内容一定要和主库show master status出来的内容一致。
sql
show slave status\G;如果看到
Slave_IO_Running:NoSlave_SQL_Running: No
就没啥问题,下面就可以开启从服务器
sql
mysql> start slave;测试,在主库创建一个新的数据库,查看从库是否复制成功。
读写分离
- 通过程序中的配置文件实现
- 通过中间件比如:
mycat等实现
使用thinkphp举例:
分库分表
应用场景
- 并发量很大,但是数据量比较少,单个服务器的 IO 就会增大,可以只分库,不分表
- 并发量不大,但数据量比较大,可以只分表,不分库,减少单个表的压力
- 当并发量和数据量都很大的时候,既要分库,也要分表
拆分
垂直拆分
- 并发分库分表顺序:先垂直分,后水平分,垂直更简单更符合实际业务
垂直分库:
分库垂直分库,针对一个系统的不同业务进行拆分,比如:用户拆分到
user库,商品拆分到goods库,订单拆分到orders库。拆分后放到不同的服务器上。在高并发下一定程度能够解决IO、连接数,硬件资源等瓶颈。
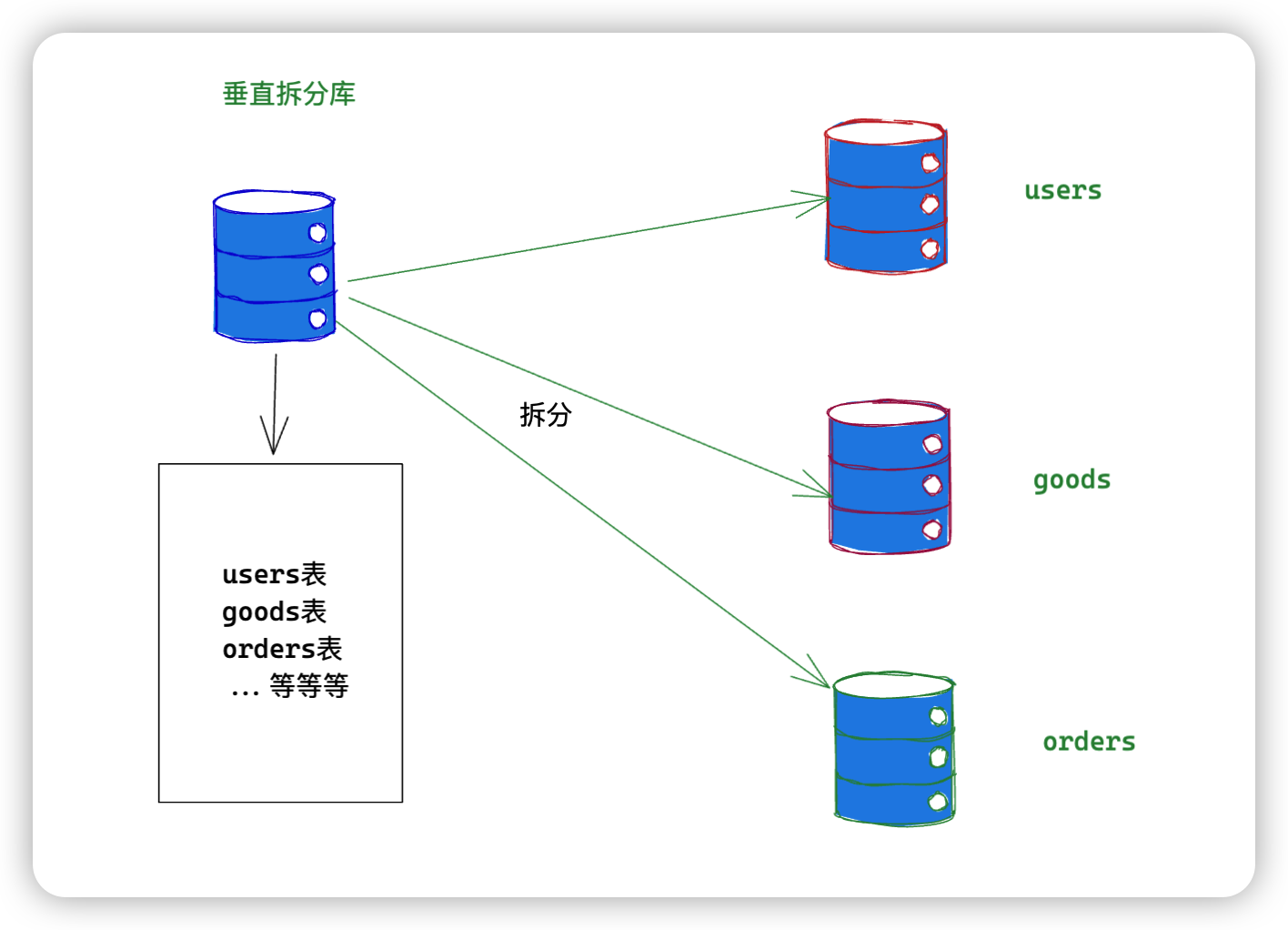
垂直分表:
”大表拆小表“,基于表中字段拆分,将不常用的,数据较大的拆分到扩展表,一般针对几百列的大表进行拆分。
特点
- 每个库、表的结构都不一样
- 每个库、表的数据至少一列一样:主键或者
xx_id - 每个库、表的并集是全量数据
优点
- 拆分后业务清晰
- 数据维护简单,按照业务放到不同的服务器中
缺点
- 单表数据量大时,写读压力还是很大
- 受业务影响,热门业务压力大,冷门业务造成资源浪费
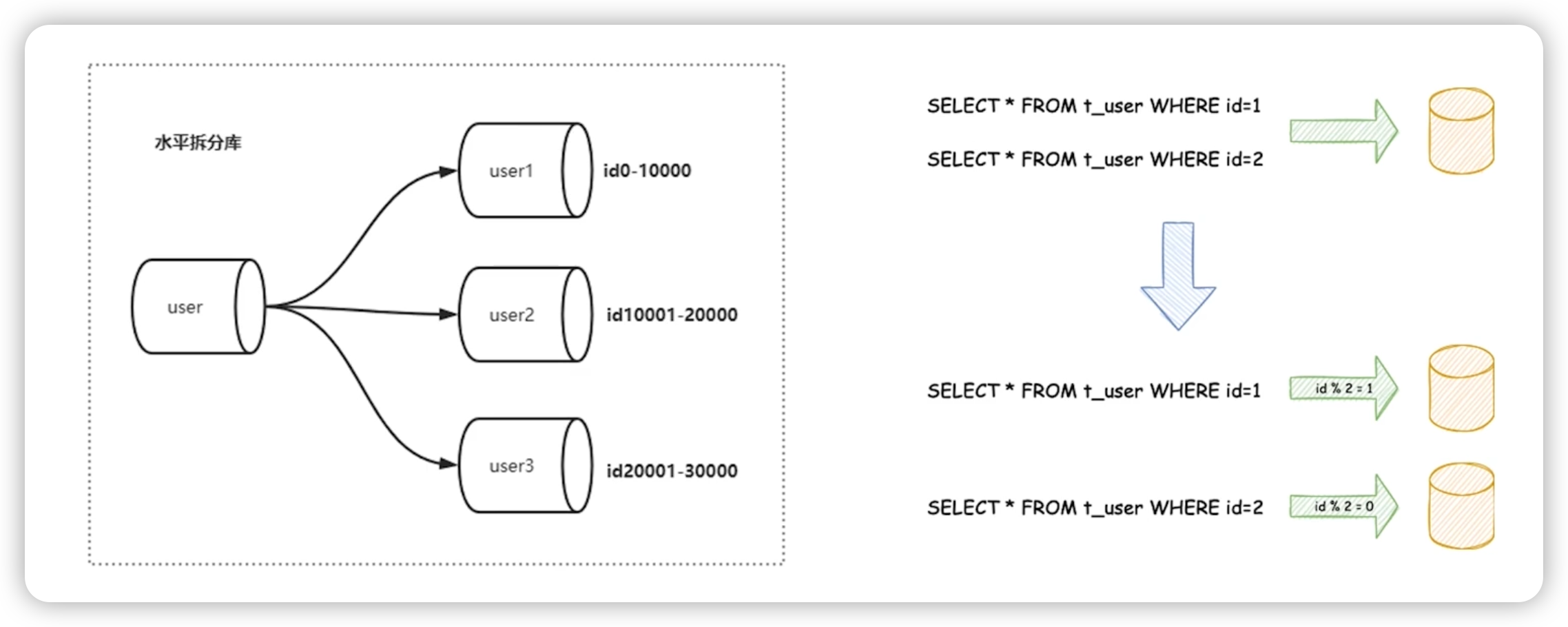
水平拆分
- 水平分表,针对数据量巨大的单标,按照某种规则,拆分到多个表中,但是这些表还是在一个库中
- 水平分库分表,按照某种规则,把拆分的表再拆到不同的库中去。
拆分规则
- 按照范围来拆分:比如
0-10000一个表,10001到20000的一个表 HASH取模,比如通过用户 ID 取模,然后分配到不同的库表中- 地理区域,比如按照华北,东北等区域划分,一般做”云“的会比较多
- 时间拆分,比如将 6 个月前的数据拆出放到一张表,随着时间的流逝,这些表的数据查询的几率很小,这也是冷热数据分离。
特点
- 每个库、表的结构都一样
- 每个库、表的数据的都不一样
- 每个库、表的并集是全量数据
优点
- 单库、表的数据减少,有利于性能
- 库、表结构相同,程序改动小
缺点
数据扩容难度大,比如取模的值变了
可以使用一致性
Hash算法来解决